
La regressione logistica è un modello statistico utilizzato per prevedere la probabilità di un evento in base a un insieme di variabili indipendenti.
E’ particolarmente utile quando si vuole classificare un evento come appartenente o meno ad una determinata categoria (ad esempio, un cliente che acquisterà o meno un prodotto, un paziente che svilupperà o meno una malattia).
Si tratta di un algoritmo di Apprendimento Automatico Supervisionato che può essere utilizzato per modellare la probabilità di una determinata classe o evento. Viene utilizzato quando i dati sono linearmente separabili – cioè se esiste una linea o un piano che possono essere utilizzati per separare i dati in diverse classi in modo univoco – e l’esito è binario o dicotomico.
Ciò significa che la regressione logistica viene solitamente utilizzata per problemi di classificazione binaria (Sì/No, Corretto/Sbagliato, Vero/Falso, ecc.),
Nel corso di questo post mostrerò come eseguire una regressione logistica binomiale per creare un modello di classificazione, al fine di prevedere risposte binarie su un determinato insieme di predittori.
Come funziona la regressione logistica e i passi per costruirla
La regressione logistica è una tecnica di modellizzazione statistica utilizzata per prevedere la probabilità di un evento binario (ad esempio, sì/no, vero/falso) in base a un insieme di variabili indipendenti.
A differenza della regressione lineare, che è utilizzata per prevedere valori continui, la regressione logistica utilizza la funzione logistica per “modellizzare” la probabilità dell’evento osservato.
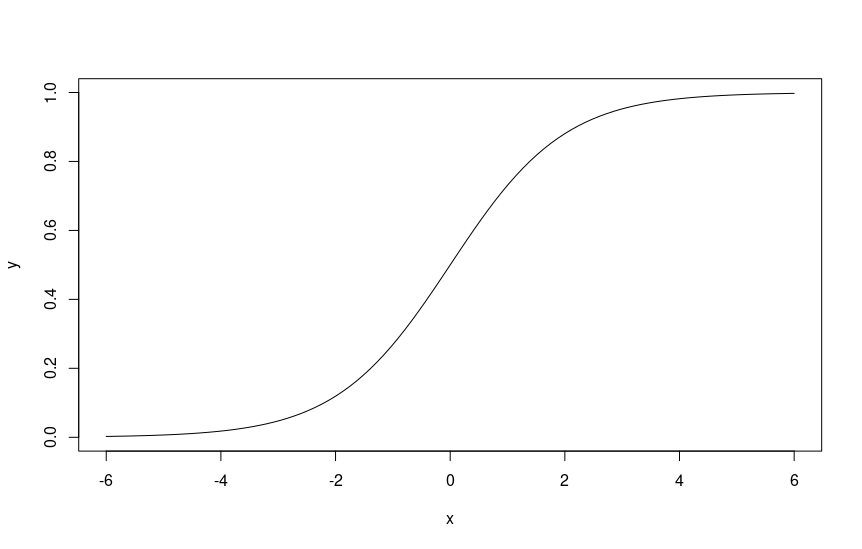
La regressione logistica utilizza la funzione logistica, anche conosciuta come sigmoide, per produrre la probabilità di un evento.
La funzione logistica produce un valore compreso tra 0 e 1, che può essere interpretato come una probabilità.
Dopo che il modello è stato addestrato, si può utilizzare per fare previsioni su nuovi dati, fornendo una stima della probabilità di un evento.
I passi per costruire una regressione logistica sono i seguenti:
- Selezionare e raccogliere i dati: raccogli i dati che desideri utilizzare per prevedere l’evento binario e seleziona le variabili indipendenti che ritieni pertinenti per la tua analisi.
- Pulire e preparare i dati: controlla i dati per eventuali valori mancanti o errati e assicurati che i dati siano adeguatamente formattati per l’analisi.
- Costruire il modello: utilizza la funzione logistica per costruire il modello sui dati di training. La funzione logistica è una funzione “S-shaped” che restituisce valori compresi tra 0 e 1, che possono essere interpretati come probabilità.
- Valutare il modello: Utilizza i dati di test per valutare l’accuratezza del modello. Ci sono varie metriche che si possono utilizzare per la valutazione, come l’accuratezza, la precisione e il recall.
- Interpretare i risultati: analizza i coefficienti del modello per capire l’importanza relativa delle variabili indipendenti e per capire meglio come i valori delle variabili influiscono sulla probabilità dell’evento.
- Utilizzare il modello per fare previsioni: utilizza il modello per fare previsioni sui nuovi dati in base alle variabili indipendenti fornite.
Questi sono ovviamente i passi generali per costruire una regressione logistica. Tuttavia, in alcune situazioni potrebbe essere necessario fare ulteriori operazioni o aggiustamenti, come ad esempio utilizzare metodi di regularizzazione per evitare problemi di overfitting, oppure utilizzare la cross-validation per avere una stima più affidabile dell’accuratezza del modello.
Un esempio in R: calcolare la probabilità di sopravvivenza sul Titanic
Pe fare un esempio pratico molto semplificato, ho scaricato un dataset tra i più noti e usati, quello relativo ai passeggeri del Titanic, che contiene informazioni sui passeggeri del famoso naufragio del Titanic, tra cui età, sesso, classe sociale e se i passeggeri sopravvissero o meno all’incidente.
Io l’ho preso da questo indirizzo e l’ho salvato in locale come titanic.csv
nb: il dataset Titanic è disponibile anche nella biblioteca di dati di Kaggle (kaggle.com) e nella raccolta di dataset UCI Machine Learning (archive.ics.uci.edu/ml/datasets.php).

Non ho bisogno in questo caso di pulire i dati, perchè utilizzo un set di dati “sicuro” e ampiamente testato.
Ovviamente, in un caso d’uso “reale” i dati andranno accuratamente esaminati, studiati, e “trattati” in fase preliminare…
Ecco allora un codice d’esempio in R:
# Carico le librerie
library(ggplot2)
library(caret)
# Carico i dati nel dataset titanic
# Sostituisco il percorso con quello nel mio pc
titanic <- read.csv("/ilmiopath/titanic.csv")
# Visualizzo le prime 10 righe
head(titanic, 10)
# Creo le variabili dummy per i campi categorici
titanic$Sex <- as.factor(titanic$Sex)
titanic$Survived <- as.factor(titanic$Survived)
# Creo un model di regressione logistica
model <- glm(Survived ~ Pclass + Sex + Age + SibSp + Parch + Fare + Embarked, data = titanic, family = binomial(link = "logit"))
# Mostro il modello
summary(model)
# Come predire la probabilita' di sopravvivenza di un caso di esempio
example <- data.frame(Pclass = 3, Sex = "male", Age = 32, SibSp = 0, Parch = 0, Fare = 8.05, Embarked = "S")
predict(model, newdata = example, type = "response")
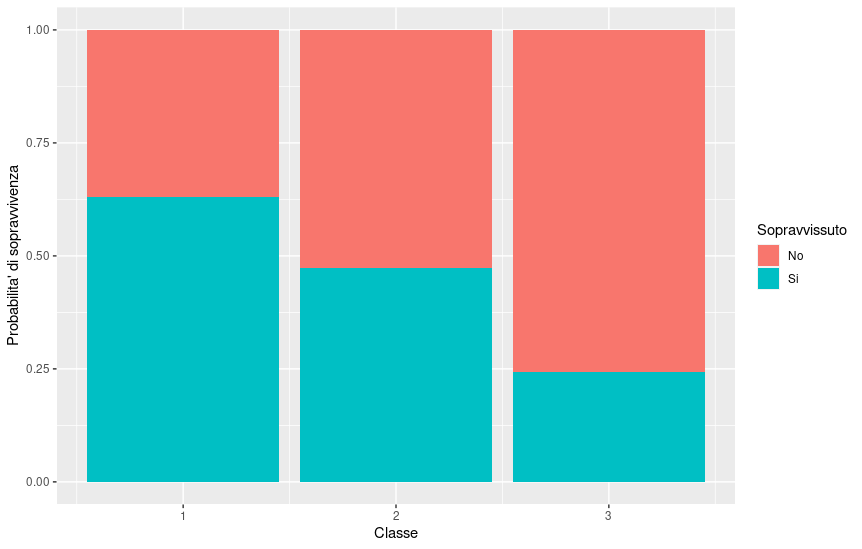
# Visualizzo graficamente le probabilita' di sopravvivenza in base alla classe
ggplot(titanic, aes(x = Pclass, fill = factor(Survived))) +
geom_bar(position = "fill") +
labs(x = "Classe", y = "Probabilita' di sopravvivenza") +
scale_fill_discrete(name = "Sopravvissuto", labels = c("No", "Si"))
In questo caso, notiamo come un uomo di 32 anni in terza classe avrebbe avuto l’8,5% circa di probabilità di sopravvivere.
Graficamente, abbiamo poi modo di visualizzare la probabilità di sopravvivenza in base alla classe del posto.
Un po’ di matematica: l’equazione logit
Come abbiamo visto, l’equazione logit è un’equazione matematica che viene usata nella regressione logistica per descrivere la relazione tra la variabile dipendente (che può assumere solo valori binari) e una o più variabili indipendenti (chiamate anche predittori o covariate).
In generale la forma dell’equazione logit è la seguente:
dove:
p è la probabilità che la variabile dipendente assuma il valore “1”
logit(p) è chiamato logaritmo del rapporto di probabilità (log-odds)
b_0, b_1, b_2, …, b_n sono i coefficienti del modello (chiamati anche pesi o parametri)
x_1, x_2, …, x_n sono le variabili indipendenti (predittori o covariate)
In sintesi, l’equazione logit descrive come la probabilità di un evento (es. una risposta binaria) dipenda dai valori delle variabili indipendenti, attraverso i pesi del modello.
Tiriamo le somme
La regressione logistica è un potente modello statistico che può aiutare a prevedere il risultato di un evento in base a un insieme di variabili indipendenti. E’ facile da usare ed interpretare, e può essere utilizzato in molti ambiti, dalla medicina alla finanza.
Rappresenta uno strumento efficace per risolvere problemi di classificazione binaria perché consente di modellare la relazione tra la variabile dipendente binaria e una o più variabili indipendenti.
Consente di:
- Modellare la relazione tra una variabile dipendente binaria e una o più variabili indipendenti.
- Prevedere la probabilità che la variabile dipendente assuma un valore specifico (es. 1 o 0) in base ai valori delle variabili indipendenti.
- Utilizzare queste previsioni di probabilità per classificare nuovi casi in base a una soglia predefinita (ad esempio, se la probabilità di un caso di essere classificato come 1 è superiore a 0.5, allora viene classificato come 1, altrimenti come 0)
- Interpretare i pesi del modello (coefficienti) per comprendere quali variabili indipendenti sono più importanti per la classificazione.
Risorse per approfondire
I titoli e le risorse a disposizione sono innumerevoli. Qualche segnalazione:
- “Applied Logistic Regression” di David W. Hosmer, Jr., Stanley Lemeshow, Rodney X. Sturdivant (in lingua inglese)
- “Introduction to Statistical Learning” di Gareth James, Daniela Witten, Trevor
- https://www.analyticsvidhya.com/blog/2015/10/basics-logistic-regression/
- https://machinelearningmastery.com/logistic-regression-for-machine-learning/