
Il concetto di distribuzione normale è uno degli elementi chiave nel campo delle ricerche statistiche. Molto spesso infatti i dati che raccogliamo mostrano delle caratteristiche tipiche, talmente tipiche da chiamare la distribuzione risultante semplicemente… “normale”.
In questo post vedremo le caratteristiche di questa distribuzione, oltre a sfiorare qualche altro concetto di notevole importanza come:
- la regola empirica
- la variabile standardizzata– Il concetto di Z score
- la disuguaglianza di Chebishev
Abbiamo visto in post precedenti esempi di distribuzioni di probabilità per variabili discrete: ad esempio la Binomiale, la Geometrica, la distribuzione di Poisson…
La distribuzione normale è una distribuzione di probabilità continua; anzi, è la più famosa e la più usata delle distribuzioni di probabilità continue. Ricordiamo al volo che una variabile continua può assumere un numero infinito di valori entro ogni intervallo dato.
La normale ha forma di campana, è detta anche gaussiana – dal nome del celebre matematico che ha fornito un contributo fondamentale a questa materia – ed è simmetrica rispetto alla sua media. Si estende indefinitamente in entrambe le direzioni, ma la maggior parte dell’area – cioè la probabilità – è raccolta attorno alla media.
La curva appare cambiare di forma in due punti, che chiamiamo punti di inflessione, e che coincidono con una distanza di una deviazione standard in più e in meno della media.
Genero con due righe in R la caratteristica forma di questa distribuzione:
Visualizzare la “normalità” dei nostri dati
R offre diversi strumenti per valutare lo scostamento di una distribuzione da una normale teorica.
Uno di questi è la funzione qqnorm(), che crea un grafico della distribuzione, in funzione dei quantili teorici normali (qq=quantile-quantile):
qqnorm(variabile) qqline(variabile)
Lo verifico con un esempio, generando una distribuzione normale:
x<- rnorm(100,5,10) qqnorm(x) qqline(x)
il risultato è questo, e come si vede abbiamo la conferma visiva della sostanziale normalità della distribuzione:
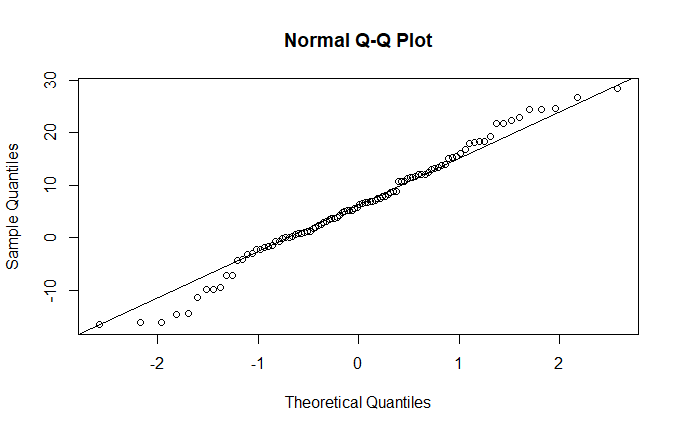
Trasformare i dati
Quando l’asimmetria di una distribuzione dipende dal fatto che una variabile si estende su svariati ordini di grandezza, abbiamo una possibilità agevole per rendere la nostra distribuzione simmetrica e simile ad una normale: trasformare la variabile nel suo logaritmo:
qqnorm(log10(variabile)) qqline(log10(variabile))
ma come calcolo in questo caso la tendenza centrale?
Se uso qualcosa tipo mean(log10(variabile)) non ho più l’unità di misura…
Per recuperarla posso usare l’antilogaritmo, cioè calcolo:
10^risultato.
Bisogna però sempre tenere a mente che questa è la media geometrica.
Bene: abbiamo il nostro set di dati e abbiamo verificato che la distribuzione è ragionevolmente simile a una normale. E’ giunto il momento di trovare delle applicazioni pratiche per mettere a frutto le nostre nuove conoscenze!
La regola empirica
La regola empirica è uno dei pilastri della statistica. Senza addentrarci troppo nei dettagli teorici, il succo è questo:
le percentuali dei dati di una distribuzione normale compresi tra 1, 2 e 3 deviazioni standard dalla media sono approssimativamente il 68%, il 95% e il 99,7%. E’ una regola di tale importanza e uso comune che è meglio riscriverla con maggiore enfasi…
LA REGOLA EMPIRICA
Le percentuali dei dati di una distribuzione normale compresi tra
1, 2 e 3 deviazioni standard dalla media
sono approssimativamente
il 68%, il 95% e il 99,7%.
Standardizzare è bello (e utile…). Lo Z score.
La distribuzione normale standardizzata è una distribuzione normale con media nulla e scarto quadratico medio (o deviazione standard, come dicono gli anglosassoni *) unitario.
* nel blog uso i due termini “scarto quadratico medio” e “deviazione standard” in maniera indifferente…poichè esprimono lo stesso concetto e sono entrambi di uso comune.
Cioè con:
\( \mu=0 \\ \sigma=1 \\ \)Qualsiasi distribuzione normale può essere convertita in una distribuzione normale standardizzata, ponendo la media uguale a zero ed esprimendo gli scarti dalla media in unità di scarti quadratici medi, quello che gli anglosassoni molto efficacemente chiamano Z-score.
Uno Z-score misura la distanza che intercorre tra un dato e la media, usando le deviazioni standard. Quindi, uno Z-score può essere positivo (l’osservazione è sopra la media) o negativo (sotto la media). Uno Z-score di -1 indicherà, ad esempio, che la nostra osservazione cade una deviazione standard al di sotto della media. Ovviamente, uno Z-score pari a 0 equivale alla media.
Lo Z-score è un valore “puro”, quindi ci fornisce un “metro di misura” di straordinaria efficacia. In pratica, è un indice che mi consente di comparare valori tra diverse distribuzioni (purchè “normali”, ovviamente), usando un “metro” standard.
Il calcolo, come abbiamo visto, è quasi banale: semplicemente divido la deviazione per lo scarto quadratico medio:
In queste condizioni, sappiamo che circa il 68% dell’area sottostante la curva normale standardizzata è compreso tra 1 scarto quadratico dalla media, il 95% entro due, il 99.7% entro tre.
Cioè:
Per trovare le probabilità – cioè le aree – per i problemi che implicano la distribuzione normale, si converte il valore X nel corrispondente Z-score:
\( Z = \frac{X-\mu}{\sigma} \\ \\ \)Quindi si cerca il valore di Z nelle tabelle e si trova la probabilità sottostante la curva compresa tra la media e Z.
Sembra difficile? E’ facilissimo, e divertentissimo. E con R, o con la TI-83, è davvero un giochetto da ragazzi!
L’importanza dello Z-score risiede anche (e soprattutto) nella sua estrema utilità pratica: consente infatti di poter raffrontare utilmente osservazioni tratte da popolazioni con differenti medie e deviazioni standard, usando una scala comune. E’ per questo che il processo si chiama standardizzazione: consente infatti di comparare osservazioni tra variabili che hanno differenti distribuzioni. Usando la tabella (o la calcolatrice o il pc) possiamo rapidamente calcolare le probabilità e i percentili, e identificare eventuali valori estremi (outliers).
Poichè sigma è positivo, Z sarà positivo se X>mu e negativo se X<mu. Il valore di Z rappresenta il numero di deviazioni standard del valore sopra o sotto la media.
Facciamo un esempio al volo
Ho delle osservazioni di un qualche fenomeno che hanno valore medio 65:
\( \mu = 65 \\ \)La deviazione standard è 10:
\( \sigma = 10 \\ \)E osservo un valore di 81 :
\( X = 81 \\\\ \)Il valore dello Z-score si calcola in un attimo:
\( Z= \frac{X – \mu}{\sigma} = \frac{81 – 65}{10} = \frac{16}{10} = 1.6 \\ \)Il valore osservato, su scala standard, cade 1,6 deviazioni standard sopra la media. Per capire dunque quale percentuale di osservazioni risultano sotto al valore osservato, mi basterà prendere la tabella:
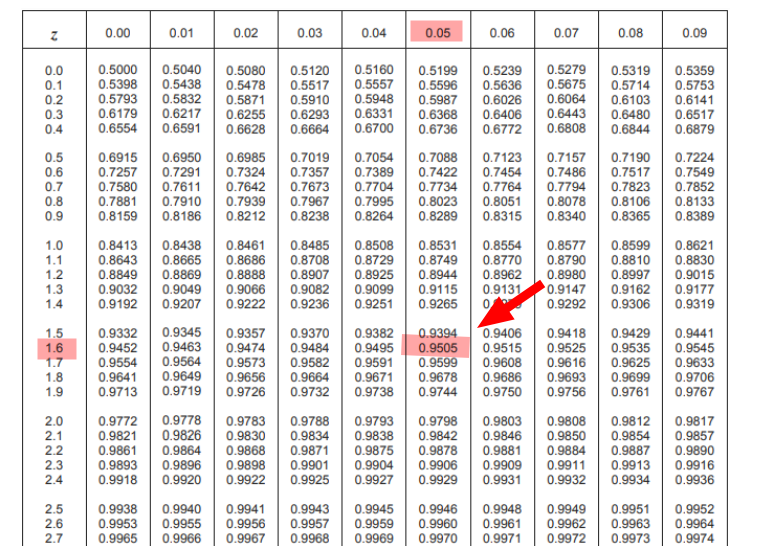
Come si nota, incrociando il mio valore z: 1,6 al livello dello 0,05 trovo il valore 0,9505, che equivale a dire che il 95,05% dei valori osservati è inferiore a 81.
Ovviamente, avrei potuto ricavare il valore in R senza usare la tabella, semplicemente con:
pnorm(1.6)
Per chi usa Python:
from scipy.stats import norm p = norm.cdf(1.6) print(p)
E ora la parte divertente: facciamo un po’ di esempi pratici!
Esempio 1
Qual è la probabilità di un evento con Z-score < 2.47 ?
Prendo in mano la tabella e vedo che 2.47 = 0.9932.
Quindi, il 99.32% dei valori si trova entro 2.47 scarti quadratici medi dalla media.
Rappresentando graficamente la situazione, quello che mi viene chiesto è di trovare l’area della superficie grigia, cioè l’area sottesa dalla curva a sinistra del punto con ascissa Z=2.47:
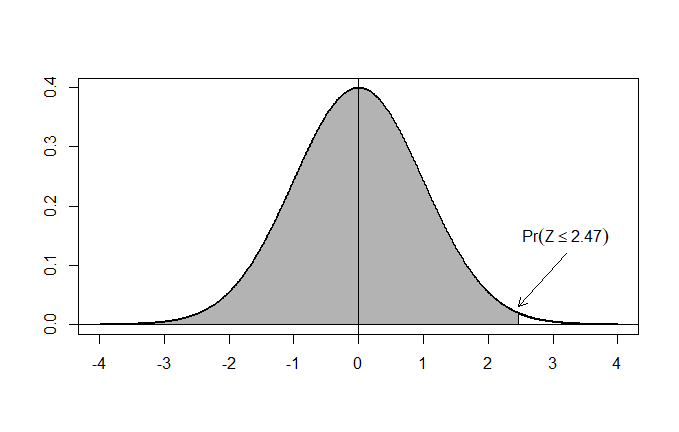
In R il calcolo è semplicissimo. Mi basta digitare:
pnorm(2.47)
La funzione pnorm() infatti ci consente di ottenere la curva della probabilità cumulativa della normale. In altri termini, ci consente di calcolare l’area relativa (ricordando che l’area totale è 1) sotto la curva, dal valore dato di Z fino a +infinito oppure -infinito.
Di default, R usa la coda inferiore, cioè trova l’area da -infinito a Z.
Per computare l’area tra Z e +infinito mi basterà settare lower.tail=FALSE.
Esempio 2
Qual è la probabilità di un valore Z-score > 1.53 ?
Dalla tabella trovo il valore 0.937, quindi deduco che il 93,7% dei valori sono sotto a Z-score 1.53.
Allora, per trovare quanti sono sopra: 100-93.7 = 6.3%
In R mi basta digitare:
1 - pnorm(1.53)
Esempio 3
Qual è la probabilità di “pescare” un valore casuale di meno di 3.65, data una distribuzione normale con media = 5 e deviazione standard = 2.2 ?
Troviamo subito lo Z-score per il valore 3.65:
\( Z= \frac{3.65 – 5}{2.2} = \frac{-1.35}{2.2} \simeq -0.61 \\ \\ \)Cerchiamo questo valore nella tabella: 0.2709. Dunque, ci sono 27.09% probabilità che un valore minore di 3.65 “esca” da una selezione casuale con media 5 e deviazione standard 2.2.
Se volessi usare una calcolatrice scientifica, con la TI83 mi basterebbe digitare:
normalcdf(-1e99,3.65,5,2.2)
Mentre con una Casio fx mi basterebbe seguire questi passi:
MENU STAT DIST NORM Ncd Data: Variable Lower: -100 Upper: 3.65 sigma: 2.2 mu: 5 EXECUTE
Il risultato ovviamente è leggermente diverso da quello ricavato dalla tabella, perchè nella tabella ho arrotondato il valore della divisione (3.65-5)/2.2 a -0.61, tralasciando la restante parte decimale…
Esempio 4 : trovare le probabilità tra 2 Z-scores
Questo è il caso più divertente di tutti. In realtà, basta trovare le 2 probabilità e sottrarre…
Qual è la probabilità associata con un valore tra Z=1.2 e Z=2.31 ?
Penso alla mia curva normale: prima trovo l’area a sinistra di Z2. Poi trovo l’area a sinistra di Z1. Quindi sottraggo i due valori per ricavare l’area tra i due, che è la probabilità cercata.
Oppure uso R e scrivo semplicemente:
pnorm(2.31)-pnorm(1.2)
e il risultato, in questo caso 10.46%, è trovato in un momento!
Un attimo, ma se volessi calcolare il valore di Z a partire da una probabilità cumulativa? Basta usare la funzione inversa di pnorm() che in R è qnorm().
Ad esempio, per trovare il valore di Z con un area 0.5, digito:
qnorm(0.5)
e otterrò il risultato, che chiaramente sarà 0 (la media di una normale standardizzata ha valore 0 e la media divide la normale in due aree uguali…).
Per chi usa Python il codice è:
from scipy.stats import norm q = norm.ppf(0.5) print(q)
La diseguaglianza di Chebyshev
La caratteristica più importante della disuguaglianza di Chebishev è che si applica ad ogni distribuzione di probabilità di cui siano noti il valore medio e la deviazione standard.
Avendo a che fare con una distribuzione di tipo ignoto oppure certamente non normale, la diseguaglianza di Chebyshev ci viene in aiuto, affermando che:
Se assumiamo un valore k reale positivo, la probabilità che la v.c. X abbia un valore compreso tra:
è maggiore di:
\( 1 – \frac{1}{k^{2}} \\ \)In altri termini: supponiamo di conoscere la media e la deviazione standard di un insieme di dati, che non seguono una distribuzione normale. Possiamo dire che per ogni valore k >0 almeno una frazione (1-1/k2) dei dati cade nell’intervallo compreso tra :
\( \mu \ – \ k \sigma \ e \ \mu \ + \ k \sigma \\\)Come sempre, un esempio è utile a chiarire il tutto. Prendo un dataset di esempio…i salari medi pagati dalle squadre di baseball USA nel 2016:
| Team | Salary ($M) |
|---|---|
| Arizona Diamondbacks | 91,995583 |
| Atlanta Braves | 77,073541 |
| Baltimore Orioles | 141,741213 |
| Boston Red Sox | 198,328678 |
| Chicago Cubs | 163,805667 |
| Chicago White Sox | 113,911667 |
| Cincinnati Reds | 80,905951 |
| Cleveland Indians | 92,652499 |
| Colorado Rockies | 103,603571 |
| Detroit Tigers | 192,3075 |
| Houston Astros | 89,0625 |
| Kansas City Royals | 136,564175 |
| Los Angeles Angels | 160,98619 |
| Los Angeles Dodgers | 248,321662 |
| Miami Marlins | 64,02 |
| Milwaukee Brewers | 51,2 |
| Minnesota Twins | 99,8125 |
| New York Mets | 128,413458 |
| New York Yankees | 221,574999 |
| Oakland Athletics | 80,613332 |
| Philadelphia Phillies | 91,616668 |
| Pittsburgh Pirates | 95,840999 |
| San Diego Padres | 94,12 |
| San Francisco Giants | 166,744443 |
| Seattle Mariners | 139,804258 |
| St, Louis Cardinals | 143,514 |
| Tampa Bay Rays | 60,065366 |
| Texas Rangers | 158,68022 |
| Toronto Blue Jays | 131,905327 |
| Washington Nationals | 142,501785 |
La media risulta: 125.3896
La deviazione standard: 48.64039
La disuguaglianza di Chebyshev
\( 1 – \frac{1}{k^{2}} \\ \)ci dice che almeno il 55.56% è in questo caso nell’intervallo:
\( (\mu − 1.5\sigma, \mu + 1.5\sigma)= (52.42902, 198.3502) \\ \\ \)