
Abbiamo avuto modo di esaminare nel corso dei precedenti post concetti come la media o lo scarto quadratico medio, capaci di descrivere una singola variabile. Si tratta di statistiche che rivestono una grande importanza; tuttavia, nella pratica quotidiana, capita sovente di dover indagare le relazioni tra due o più variabili. Ecco dunque emergere nuovi concetti chiave: la correlazione e l’analisi di regressione.
La correlazione e l’analisi della regressione sono strumenti assai utilizzati durante l’analisi dei nostri set di dati.
Implicano la stima della relazione tra una variabile dipendente e una o più variabili indipendenti.
- La Regressione semplice
- Il coefficiente di correlazione r di Pearson
- Il coefficiente di determinazione r2
- Troviamo l’equazione di regressione
- Valori anomali e punti di influenza
- Le assunzioni del modello
- Analisi dei residui
- L’analisi di regressione: difficoltà pratiche
- Altri tipi di coefficienti di correlazione
La Regressione semplice
Possiamo considerare la regressione come un metodo idoneo a ricercare una relazione matematica che esprima un legame tra un carattere y (la variabile dipendente o variabile responso) ed un carattere x (variabile indipendente o variabile predittiva).
Il primo passo utile per indagare qualitativamente l’eventuale dipendenza fra due variabili x e y consiste sempre nel disegnare un grafico, chiamato diagramma di dispersione (scatterplot).
Poniamo in ascissa i dati relativi a una delle due variabili, in ordinata quelli relativi all’altra variabile e rappresentiamo con dei punti le singole osservazioni. Ricordiamo infatti che i grafici a dispersione confrontano due variabili.
Se esiste una relazione semplice fra le due variabili, il diagramma dovrebbe mostrarla!
Usiamo dei valori di esempio e lasciamo a R il compito di tracciare a video il nostro diagramma di dispersione.
Riporto in un file csv dei dati di fantasia relativi a una ipotetica correlazione tra la temperatura ambientale registrata nella mia città e le vendite di gelati. Chiamo il file gelati.csv e lo salvo come pure testo in una cartella qualsiasi del mio filesystem (nel mio esempio in tmp/gelati.csv). Il file avrà questo contenuto:
temperatura,gelati 25,58 30,70 29,61 26,53 25,48 28,66 24,47 22,47 20,40 18,29 22,33
Ora apro R Studio e carico il mio dataset:
gelati <- read.csv("/tmp/gelati.csv")
Poi traccio il grafico scatterplot per vedere se la figura è compatibile con una ipotesi di regressione lineare:
plot(gelati)
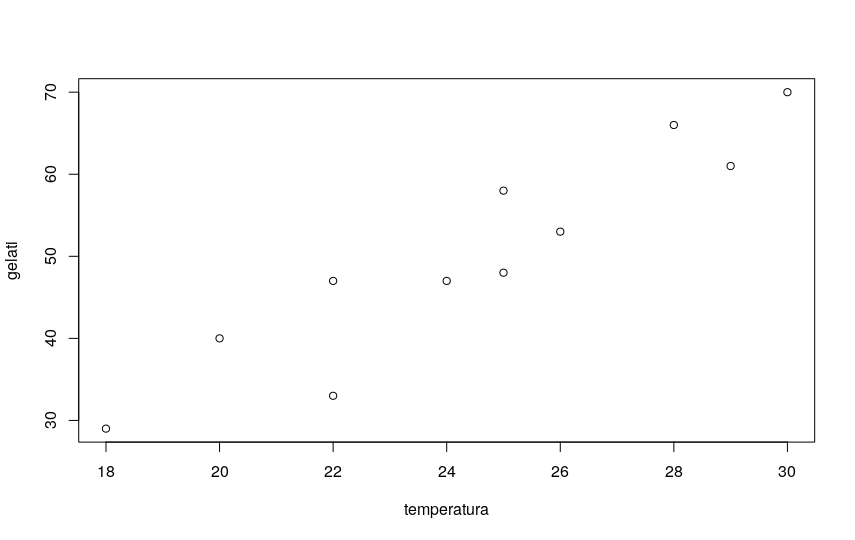
Il diagramma mostra una evidente correlazione di tipo lineare, con tendenza ascendente.
Il coefficiente di correlazione r di Pearson
Esistono in statistica svariati tipi di coefficienti di correlazione. Qualora la relazione da indagare sia tra due variabili di tipo intervallo oppure rapporto (si tratta quindi di variabili di tipo quantitativo, numeriche), il più noto e il più usato è certamente il coefficiente di correlazione di Pearson, generalmente indicato con la lettera r.
Uso il linguaggio R (da non confondere con il coefficiente r) per un esempio pratico con il coefficiente di correlazione di Pearson.
La funzione da utilizzare è cor():
cor(gelati$temperatura,gelati$gelati) [1] 0.9320279
Come si vede la correlazione in questo esempio è davvero molto forte.
r infatti è un valore standardizzato e va da +1 a -1. Più si allontana da zero e si avvicina a 1 (o a -1 in caso di correlazione negativa), più è forte la correlazione.
Se r è positivo la correlazione è positiva, cioè y aumenta all’aumentare di x .
Se r è negativo, y diminuisce all’aumentare di x.
Ma quando posso dire che una correlazione è forte o molto forte e quando moderata o addirittura nulla? La risposta è…dipende 🙂
Non esiste una risposta standard. In maniera molto arbitraria possiamo dire che in genere una correlazione sotto a 0.20 (o per meglio dire, tra -0.2 e +0.2) è considerata molto debole, tra 0.2 e 0.5 (o tra -0.2 e -0.5) moderata, tra 0.5 e 0.8 (o tra -0.5 e -0.8) piuttosto forte. Correlazioni superiori a 0.8 o inferiori a -0.8, molto forti, sono in realtà abbastanza rare.
ATTENZIONE 1 : La cosa in realtà più importante è che l’evidenza di una relazione tra due variabili non implica necessariamente la presenza di un rapporto di causa effetto tra le due variabili. E’ un punto della massima importanza, che va sempre tenuto bene a mente. Entrambe le variabili che nel mio studio mostrano una fortissima correlazione possono in realtà dipendere da una terza variabile, o da molte altre variabili, che costituiscono la reale causa. Trovare e calcolare la correlazione tra due variabili è relativamente semplice, trovare e soprattutto provare un rapporto di causa ed effetto è estremamente complesso!
ATTENZIONE 2: Un altro punto che vorrei sottolineare è che il coefficiente di correlazione r di Pearson misura la correlazione lineare tra due variabili. Questo significa che due variabili possono mostrare una correlazione apparente nulla (r circa 0) eppure essere correlate, ad esempio mostrando una correlazione di tipo curvilineo. Un classico esempio di scuola riguarda la correlazione tra il livello di stress e la prestazione in una prova di esame. Un leggero stress infatti contribuisce a migliorare la prestazione, ma superata una certa soglia risulta del tutto dannoso, portando a un decadimento del risultato. In questo caso, l’analisi in termini di r e di correlazione lineare porterebbe a scartare una correlazione invece esistente.
E ora on po’ di matematica (ma davvero poca)
Il coefficiente di correlazione di Pearson per una popolazione, date due variabili X e Y, si indica con la lettera greca rho ed è dato da:
dove:
- COV indica la covarianza
- σX è la deviazione standard di X
- σY è la deviazione standard di Y
- μx è la media della popolazione per x
- μy è la media della popolazione per y
- n è il numero di elementi in entrambe le variabili
- i è l’indice che va da 1 a n
- Xi è un singolo elemento della popolazione x
- Yi è un singolo elemento della popolazione y
Per calcolare la covarianza della popolazione (che, ricordiamo, è una misura non standardizzata della direzione e della forza della relazione tra gli elementi di due popolazioni):
\( \sigma_{XY}=\frac{\sum\limits_{i=1}^n (X_i-\mu_x)(Y_i-\mu_y)}{n} \\ \)dove:
Attenzione: per calcolare i valori per quanto riguarda una popolazione stimata, basterà usare al denominatore sempre n-1.
Di default R usa sempre deviazione standard campionaria, quindi il valore calcolato della r di Pearson sarà sempre calcolato con n-1 al denominatore.
Tiro fuori la calcolatrice – o carta e penna – e faccio un po’ di conti…
questa è la mia tabella, che ho completato computando i vari valori:
| temperatura | gelati | xi-X | yi-Y | (xi-X)-(yi-Y) | |
|---|---|---|---|---|---|
| 1 | 25 | 58 | 0.55 | 7.82 | 4.26 |
| 2 | 30 | 70 | 5.55 | 19.82 | 109.90 |
| 3 | 29 | 61 | 4.55 | 10.82 | 49.17 |
| 4 | 26 | 53 | 1.55 | 2.82 | 4.36 |
| 5 | 25 | 48 | 0.55 | -2.18 | -1.19 |
| 6 | 28 | 66 | 3.55 | 15.82 | 56.08 |
| 7 | 24 | 47 | -0.45 | -3.18 | 1.45 |
| 8 | 22 | 47 | -2.45 | -3.18 | 7.81 |
| 9 | 20 | 40 | -4.45 | -10.18 | 45.36 |
| 10 | 18 | 29 | -6.45 | -21.18 | 136.72 |
| 11 | 22 | 33 | -2.45 | -17.18 | 42.17 |
La somma dei valori dell’ultima colonna è 456.0909.
Posso quindi calcolare la covarianza dividendo per n-1 = 10, quindi:
456.0909/10 = 45.60909
Calcolando le deviazioni standard campionarie per X e Y, trovo i valori:
Sx = 3,751363
Sy = 13,04468
Quindi Sx * Sy = 48,9353299
Ultimo passaggio. Posso calcolare r:
45,60909 / 48,9353299 = 0,9320278435
che come si vede coincide perfettamente con il valore fornito dalla funzione cor() di R.
Il coefficiente di determinazione r2
Elevando r al quadrato otteniamo il coefficiente di determinazione.
Nel nostro caso il coefficiente di determinazione r2 sarà:
R-squared = 0.86868
ma cosa significa questo numero?
r2 ci segnala in quale misura la nostra equazione di regressione riproduce la varianza dei dati.
Detta in altri termini, quanta parte della variazione della variabile responso è spiegata dalla variabile predittiva. Più è accurata l’equazione di regressione, più il valore di r2 tende a 1.
La funzione cor() in R consente di ottenere facilmente i valori di correlazione calcolati attraverso tutti questi metodi, come si vede facilmente dalla sintassi della funzione:
cor(x, y = NULL, use = "everything", method = c("pearson", "kendall", "spearman"))
Troviamo l’equazione di regressione
Il nostro scopo è quello di ottenere l’equazione di regressione, e trattandosi di una regressione lineare la forma tipica sarà:
y = mx + b
m indica la pendenza della retta nel grafico, e si chiama coefficiente di regressione.
b è il punto in cui la retta interseca l’asse delle y, e si chiama intercetta.
Ricordiamo sempre che la retta di regressione lineare è la retta che meglio si adatta ai dati forniti. Idealmente, vorremmo ridurre al minimo le distanze di tutti i punti dati dalla linea di regressione. Queste distanze sono chiamate errore e sono anche note come valori residui. Una buona linea avrà piccoli residui.
Adattiamo la linea di regressione ai punti dati in un grafico a dispersione utilizzando il metodo dei minimi quadrati.
I calcoli non sono difficili (non riporto in questa sede il procedimento), ma la procedura può essere tediosa. Per questo, tutte le calcolatrici scientifiche evolute e molti fogli elettronici e programmi forniscono procedure che ci semplificano la vita.
Usando R, il processo è ancora più agevole.
Procedo calcolando i parametri della retta di regressione:
# calcolo i parametri della retta di regressione lm(gelati$gelati ~ gelati$temperatura) Call: lm(formula = gelati$gelati ~ gelati$temperatura) Coefficients: (Intercept) gelati$temperatura -29.074 3.241
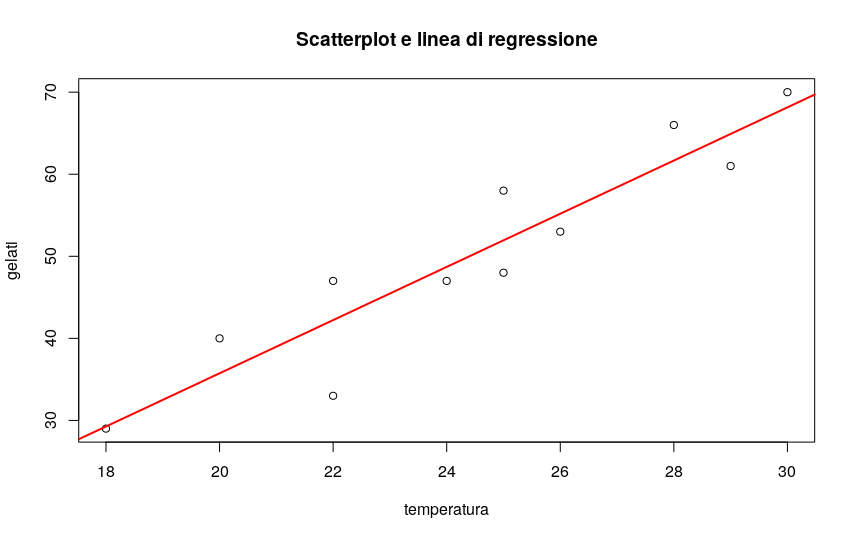
Dunque la mia retta avrà equazione:
y = 3,241x - 29,074
E’ giunto il momento di tracciare di nuovo il diagramma a dispersione, sovrapponendo la linea di regressione che ho appena trovato:
# disegno lo scatterplot plot(gelati$temperatura,gelati$gelati, main="Scatterplot e linea di regressione",xlab="temperatura", ylab="gelati") # e traccio la linea di regressione in rosso abline(lm(gelati$gelati ~ gelati$temperatura),col="red",lwd=2)
Valori anomali e punti di influenza
Un valore anomalo è un’osservazione estrema che non si adatta alla correlazione generale o al modello di regressione. In pratica, nel nostro grafico vedremo che tali valori anomali, qualora esistano, saranno molto lontani dalla linea di regressione nella direzione y.
L’inclusione di un valore anomalo può influenzare la pendenza e l’intercetta y della retta di regressione.
Quando si esamina un grafico a dispersione e si calcola l’equazione di regressione, vale la pena considerare se le osservazioni anomale debbano essere incluse o meno. Potrebbe infatti trattarsi di errori nei dati – e allora sarebbero da escludere – ma anche di valori “reali”, e in tal caso si tratta di informazioni della massima importanza per l’analista.
Ma quando possiamo parlare di valori anomali? Non esiste una regola fissa quando si cerca di decidere se includere o meno un valore anomalo nell’analisi di regressione. Questa decisione dipende dalla dimensione del campione, da quanto è estremo il valore anomalo e dalla normalità della distribuzione.
Per i dati univariati, si può utilizzare una regola empirica basata sull’intervallo interquartile IQR per determinare se un punto è o meno un valore anomalo.
Procediamo in questo modo:
- Calcoliamo l’intervallo interquartile per i nostri dati.
- Moltiplichiamo l’intervallo interquartile (IQR) per 1,5.
- Aggiungiamo 1,5 x (IQR) al terzo quartile.
Qualsiasi numero maggiore del valore trovato è un dato estremo sospetto. - Sottraiamo 1,5 x (IQR) dal primo quartile. Qualsiasi numero inferiore è un dato estremo sospetto.
Un punto influente è un punto che, se rimosso, produce un notevole cambiamento nella stima del modello. Un punto influente può essere o meno un valore anomalo (outlier).
Il comando influence.measures() fornisce tutta una serie di utili misure di influenza: dfbeta, dffit, covratio, distanza di Cook e punti di leverage di tutte le osservazioni:
# misuro punti di influenza influence.measures(lm(gelati$gelati ~ gelati$temperatura))
Le assunzioni del modello
Perchè il modello di regressione lineare possa risultare effettivamente utilizzabile, devono essere rispettate alcune assunzioni:
- Distribuzione normale degli errori: gli errori devono avere, per ogni valore di X, una distribuzione normale.
- Omoschedasticità: la variabilità degli errori è costante per ciascun valore di X.
- Indipendenza degli errori: gli errori devono essere indipendenti per ciascun valore di X (è importante soprattutto per osservazioni nel corso del tempo, nelle quali deve essere verificato che non sia presente autocorrelazione).
Occorre dunque effettuare specifici test del modello, e tutti devono dare esito positivo per far sì che il modello di stima possa essere considerato corretto.
Se anche uno solo dei test dà esito negativo (non normalità dei residui, eteroschedasticità, correlazione seriale) il metodo di stima attraverso i minimi quadrati non va bene.
Analisi dei residui
Il residuo è uguale alla differenza tra valore osservato e il valore previsto di Y.
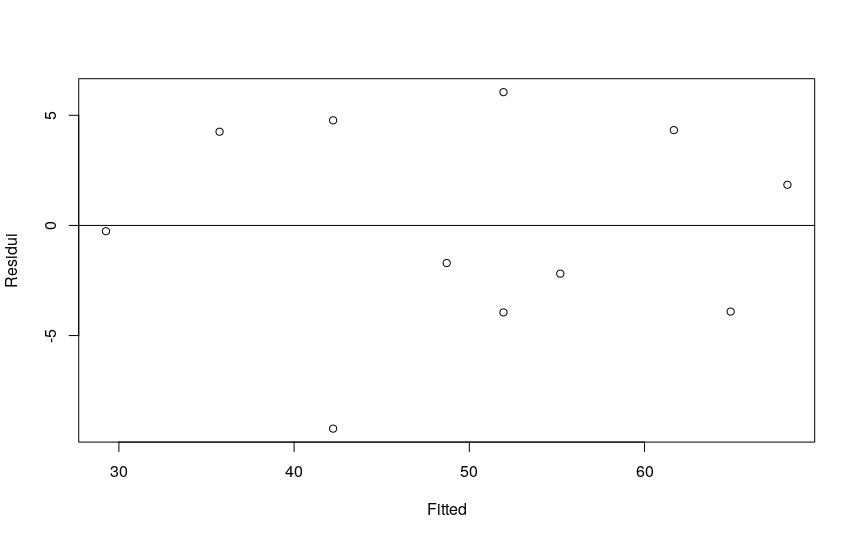
- Per stimare la capacità di adattamento ai dati della retta di regressione è opportuna un’analisi grafica tramite un grafico di dispersione dei residui (in ordinata) e dei valori di X (nelle ascisse).
- Per verificare le assunzioni posso valutare il grafico dei residui rispetto a X: questo ci consente di stabilire se la variabilità degli errori varia a seconda dei valori di X, confermando o meno l’assunzione di omoschedasticità.
- Per verificare la linearità occorre tracciate il grafico dei residui, in ordinata, rispetto ai valori previsti, in ascissa. I punti dovrebbero essere distribuiti in modo simmetrico intorno ad una linea orizzontale con intercetta uguale a zero. Andamenti diversi indicano la presenza di non linearità.
# guardo la distribuzione dei residui. # deve essere bilanciata sopra e sotto la linea di zero. lmgelati <- lm(gelati$gelati ~ gelati$temperatura) plot (lmgelati$residual ~ lmgelati$fitted, ylab="Residui", xlab="Fitted") abline(h=0)
Il pacchetto lmtest di R ci mette a disposizione il test di Breusch-Pagan per verificare l’omoschedasticità dei residui:
# verifico omoschedasticita dei residui # utilizzando il test di Breusch-Pagan library(lmtest) testbp <- bptest(gelati ~ temperatura, data=gelati) testbp
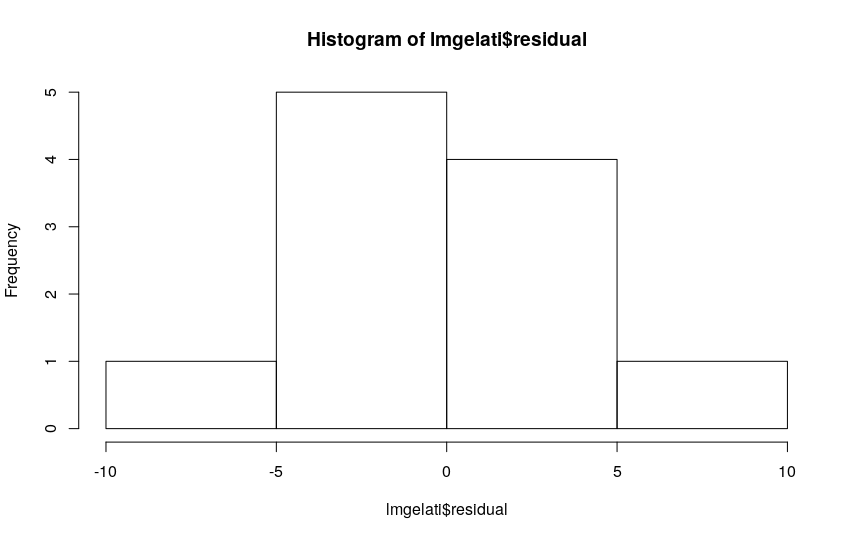
Per quanto riguarda la normalità dei residui, l’istogramma delle frequenze consente di verificare o meno la condizione.
Possiamo verificare la normalità dei residui anche numericamente, tramite un test di Shapiro – Wilcox:
# verifico la normalita della distribuzione degli errori # con un test shapiro-wilcox residui <- residuals(lm(gelati$gelati ~ gelati$temperatura)) shapiro <- shapiro.test(residui) shapiro
Verifichiamo che la media degli errori non sia significativamente diversa da zero. Per far questo possiamo ricorre a un test t di Student:
residui <- residuals(lm(gelati$gelati ~ gelati$temperatura)) t.test(residui)
Il grafico dei residui rispetto al tempo (e l’utilizzo della statistica di Durbin-Watson) consente invece di evidenziare l’esistenza o meno di autocorrelazione.
# test Durbin Watson per autocorrelazione dwtest(gelati$temperatura~gelati$gelati)
L’analisi di regressione: difficoltà pratiche
L’analisi di regressione semplice è un modello assai utilizzato, ma molto, molto insidioso. La tendenza generalizzata, infatti, è quella di impiegare questo tipo di analisi in maniera poco consapevole e rigorosa – come ad esempio nell’esempio semplificato che ho proposto 🙂
Le assunzioni alla base del modello sono piuttosto stringenti, e molto spesso ignorate…
Frequentemente, l’analisi viene svolta senza tenere conto del modo in cui tale assunzioni debbono essere valutate oppure si sceglie il semplice modello di regressione semplice lineare al posto di modelli alternativi più calzanti.
Un altro errore molto comune è dato dall’estrapolazione: si compie cioè una stima di valori esterni all’intervallo dei valori osservati. Questo è un grande no-no.
Il consiglio è sempre quello di iniziare l’analisi guardando con grande attenzione il diagramma di dispersione e di verificare con attenzione le ipotesi alla base del modello di regressione prima di usare i risultati.
Altri tipi di coefficienti di correlazione
Il coefficiente di correlazione di Pearson è sicuramente il più conosciuto, studiato e usato, ma come abbiamo visto si applica nei casi in cui entrambe le variabili siano di tipo quantitativo, misurate attraverso una scala di tipo intervallo oppure rapporto. Esistono altri metodi che ci consentono di ottenere la misura della correlazione tra variabili di tipo diverso. Tutti condividono la caratteristica di essere concettualmente molto simili al coefficiente r di Pearson.
Il coefficiente di correlazione punto-biseriale
Prendiamo il caso di un’analisi nella quale una delle variabili sia di tipo quantitativo (misurata su una scala intervallo oppure rapporto) e la seconda sia una variabile categorica a due livelli (o variabile dicotomica). In questo caso ci viene in aiuto il coefficiente di correlazione punto-biseriale. Non approfondisco in questa sede il concetto, trattandosi di fatto di una versione “speciale” del coefficiente di Pearson, lasciando al lettore l’approfondimento quando richiesto dall’analisi.
Il coefficiente phi
Se dovesse servirci di conoscere se due variabili dicotomiche sono correlate, potremmo poi ricorrere al coefficiente phi, un altro caso “speciale” del coefficiente r di Pearson. Molti lettori sapranno certamente che due variabili dicotomiche possono anche essere analizzate servendosi di un test chi quadrato.
Il coefficiente di correlazione per ranghi rho di Spearman (e un accenno al tau di Kendall)
Talvolta poi i dati sono riportati in termini di ranghi. I ranghi sono una forma di dati di tipo ordinale, e dal momento che gli altri tipi di coefficienti di correlazione non trattano questa tipologia di dati, ecco la necessità di introdurre l’uso del coefficiente rho di Spearman. La correlazione di Spearman segue un approccio semplice e ingegnoso: si converte ogni set di dati in ranghi e quindi si calcola la correlazione. E’ una misura statistica non parametrica di correlazione: l’unica ipotesi richiesta è che le variabili siano ordinabili, e possibilmente continue.Ecco la formula del coefficiente di Spearman:
\( \\ r_s=\frac{6\sum{d}_i^2}{N(N^2-1)} \\ \\ \)Anche rs può assumere valori compresi tra –1.00 e +1.00, con gli stessi significati visti per r.
Il coefficiente rs ha un grave difetto: può dare una stima per eccesso della correlazione tra X e Y se, per almeno una delle due variabili, si riscontrano molti ranghi uguali. Per questo motivo, per misurare la correlazione tra due variabili di tipo ordinale, si ricorre spesso a un’altra statistica: il coefficiente tau di Kendall.