
Analysis of Variance (ANOVA) is a parametric test that evaluates the differences between the means of two or more data groups.
It is a statistical hypothesis test that is widely used in scientific research and allows to determine if the means of at least two populations are different.
As a minimum prerequisite, a continuous dependent variable and a categorical independent variable that divides the data into comparison groups are required.
The term “analysis of variance” comes from the way the analysis uses variances to determine if the means are different.
ANOVA works by comparing the variance of the means between the groups (called between variance) with the variance within the individual groups (or within variance).
Analysis of Variance was developed by the great statistician Ronald Fisher (we could say he is one of the Gods in the Olympus of statistics).
It is no coincidence that ANOVA is based on a distribution called the F distribution.

(from Wikipedia)
ANOVA: a parametric test
ANOVA is a parametric test. Therefore, it requires that a certain number of requirements are met:
- Normality. The data in the groups must follow a normal distribution.
- Homogeneity of variances: the groups should have approximately equal variances.
- The residuals follow the least squares assumptions.
- There is at least one categorical independent variable (factor).
- The dependent variable is continuous.
- The observations are independent.
Why ANOVA and not a series of t-tests?
A question that is legitimate to ask is: why should I use ANOVA when I can use a series of comparisons between each group and each of the others?
The answer is not simply related to the boredom and difficulty of having to perform a large number of tests (for example, for 4 factors I would need to perform 6 different t-tests). The biggest problem is that the probability of committing a Type I error increases with an exponential progression. We know that if we choose a typical alpha of 0.05, we set the probability of incurring a Type I error at 5%.
If we call n the number of t-tests to be performed, we will have an overall probability of committing Type I errors equal to:
in our example this means:
\( 1-(1-0,05)^6 = \\ 1-0,735 = \\ 0,265 \\ \\ \)That is, a Type I error probability of 26.5%! Clearly unacceptable… When we want to test the mean of 3 or more groups, ANOVA is certainly preferable to a series of T-tests.
The simplest case: One-way ANOVA
The simplest type of ANOVA test is one-way ANOVA. This method is a generalization of t-tests capable of evaluating the difference between more than two group means.
The data is organized into various groups based on a single categorical variable (called the factor variable).
As we said, ANOVA is a hypothesis test. In this case, we have a null hypothesis H0:
the means between the different groups are equal
and an alternative hypothesis Ha:
at least one mean is different.
ATTENTION: ANOVA tells us IF a mean is different, not WHICH group has a different mean. For that, we will need an additional step, the post hoc test, which we will see in due course.
The “classic” (and a bit tedious) way to perform an ANOVA test: the ANOVA table
It is true that using the “classic” way of computing the result of an ANOVA test can provide important theoretical notions, but it is also true that anyone who uses this type of test in everyday life rarely – if not never – uses paper and pencil and fills out an ANOVA table… The convenience of R functions in doing all the “hard work” with a click is really priceless. However, a step-by-step example will provide us with an important introduction.
The steps we will take can be schematized as follows:
- We will calculate the common variance, called the within-sample variance S2within, or residual variance.
- We will calculate the variance between the sample means, so:
The mean of each group
The variance between the sample means (S2between) - And then we will derive the F statistic as the ratio between S2between/S2within
Since SEO is one of the fields I follow with the greatest interest, I hypothesize an example (obviously devoid of real value) that deals with the analysis of website traffic data.
My independent variable with multiple factors is the type of device used by the visitors: desktop, mobile, tablet.
My dependent variable will be the objectives achieved on the site.
Suppose we follow the monthly data for 6 months and obtain these measurements:
| Desktop | Mobile | Tablet |
| 39 | 45 | 30 |
| 67 | 54 | 45 |
| 78 | 64 | 22 |
| 59 | 52 | 39 |
| 42 | 46 | 38 |
| 51 | 35 | 41 |
I’ll calculate the mean value for the Desktop group:
(39+67+78+59+42+51)/6 = 56
I calculate the mean for Mobile:
(45+54+64+52+46+35)/6 = 49.3
And the one for Tablets:
(30+45+22+39+38+41)/6 = 35.83
Let’s move on to calculating the sums of squares:
| Desktop | Mobile | Tablet |
| (39-56)2 = 289 | (45-49.3)2 = 18.49 | (30-35.83)2 = 33.99 |
| (67-56)2 = 121 | (54-49,3)2 = 22.09 | (45-35.83)2 = 84.09 |
| (78-56)2 = 484 | (64-49,3)2 = 216.09 | (22-35.83)2 = 191.27 |
| (59-56)2 = 9 | (52-49,3)2 = 7.29 | (39-35.83)2 = 10.05 |
| (42-56)2 = 196 | (46-49,3)2 = 10.89 | (38-35.83)2 = 4.71 |
| (51-56)2 = 25 | (35-49,3)2 = 204.49 | (41-35.83)2 = 26.73 |
| Total | Total | Total |
| 1124 | 479.34 | 350.84 |
We are ready to derive SSe, the sum of squared errors:
SSe = 1124 + 479.34 + 350.84 = 1954.18
We calculate the Grand Mean of all observations by summing the values of the desktop, mobile, and tablet groups and dividing by the number of observations:
(336+296+215)/18 = 47
Let’s proceed with the calculation using a table:
| A-Observations | B-Grand Mean | C-Mean | (B-C)2 | A * D | |
| Desktop | 6 | 47 | 56 | 81 | 486 |
| Mobile | 6 | 47 | 49.3 | 5.29 | 31.74 |
| Tablet | 6 | 47 | 35.83 | 124.77 | 748.62 |
And we find the Sum of Squares between:
SSb = 486 + 31.74 + 748.62 = 1266.4
Just a bit more effort, and now it gets interesting!
The between degrees of freedom df1 are equal to N – 1, thus:
3 – 1 = 2
The within degrees of freedom df2 are equal to N – K, thus:
18 – 3 = 15
Let’s find the Mean Square Error, MSe:
\( MS_e=\frac{SS_e}{df_2} \\ \frac{1954.18}{15} = 130.3 \\ \\ \)And the Mean Square between:
\( MS_b=\frac{SS_b}{df_1} \\ \frac{1266.4}{2}=633.18 \\ \\ \)The moment has arrived: we can finally determine our F value!
\( F=\frac{MS_b}{MS_e} \\ \frac{633.18}{130.3}=4.86 \\ \)I’ve finally found the value I was looking for, F=4.86.
Now, I just need to consult an F distribution table and find the critical value corresponding to the intersection of the df2/df1 values.
That value is 3.68.
My F value of 4.86 falls into the rejection zone for the null hypothesis H0.
My test, with an alpha value of 0.05, indicates that the means of the three groups are not equal.
What an effort… It’s time to harness the power of R
The example values are available in this csv file.
Assuming our csv file is in the home directory, I can create an R script in Rstudio and load my very simple dataset:
obiettivianova <- read.csv("~/anova-ex1.csv")
A graphical look at the values for the three groups:
boxplot(obiettivianova$obiettivi ~ obiettivianova$device, main="Boxplot objectives by device", xlab="Device", ylab="Objectives")
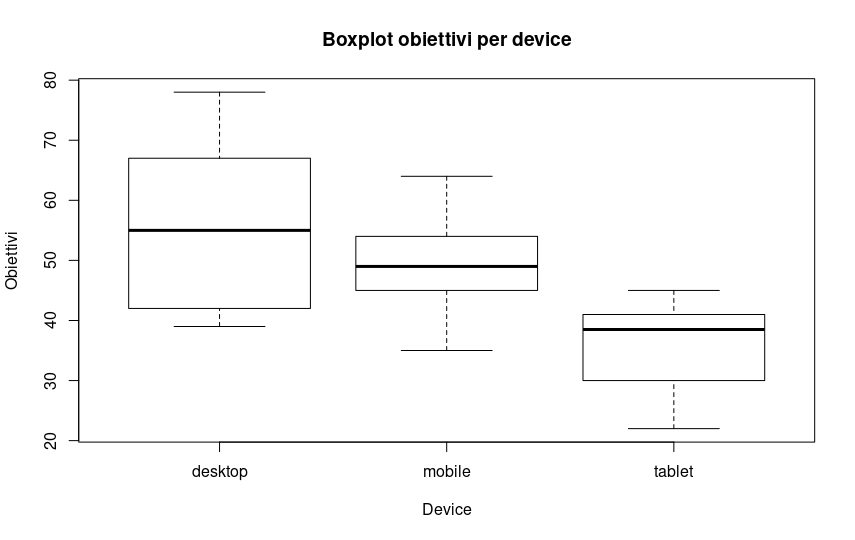
The boxplot already seems to suggest something, but we proceed analytically.
Let’s take a look at the means:
aggregate(objectives ~ device, obiettivianova, mean)
device objectives 1 desktop 56.00000 2 mobile 49.33333 3 tablet 35.83333
and proceed with our test:
my_model <- aov(obiettivianova$objectives ~ obiettivianova$device) summary(my_model)
The output we obtain is as follows:
Df Sum Sq Mean Sq F value Pr(>F) obiettivianova$device 2 1267 633.4 4.862 0.0236 * Residuals 15 1954 130.3 --- Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
The power of R is clear here. In just moments, we have a wealth of useful information. The F value is 4.862, degrees of freedom are 2, etc., etc.
There’s no need to consult the F distribution table (or use the corresponding R command) because the p-value is already present, indicating rejection of the null hypothesis at the 5% level (p = 0.0236 < 0.05).
ANOVA tells us that the means are not all equal. It’s time for a post-hoc test to evaluate where the “anomaly” lies:
TukeyHSD(my_model)
The Tukey HSD Test is one of the most useful post hoc tests for cases like this. The output we get is:
diff lwr upr p adj mobile-desktop -6.666667 -23.78357 10.450234 0.5810821 tablet-desktop -20.166667 -37.28357 -3.049766 0.0204197 tablet-mobile -13.500000 -30.61690 3.616900 0.1348303
As you can see, while for the comparisons between mobile-desktop and tablet-mobile means we cannot reject the null hypothesis, the same cannot be said for the tablet-desktop means, where the difference is statistically significant.